
Why We Built BenchTest: Solving the Container Resource Sizing Problem
Discover why we built BenchTest to solve the critical problem of container resource sizing in Kubernetes, and how it helps developers optimize their workloads.
Why We Built BenchTest: Solving the Container Resource Sizing Problem
Getting container resource sizing right is one of the most challenging aspects of running applications in Kubernetes. Too little resources, and your application crashes or performs poorly. Too much, and you're burning money on idle capacity.
According to Datadog's research, over 65% of containers use less than half of their requested CPU and memory [1]. This means most teams are significantly over-provisioning their workloads, leading to unnecessary costs and inefficient resource utilization.
This is exactly why we built BenchTest. To help developers solve this problem before it becomes a production issue.
The Resource Management Challenge
In Kubernetes, a container requests a set of resources as part of its pod specification. The scheduler takes these requests into account when deciding where to place pods in the cluster. These requests dictate how your cluster's capacity is allocated, affecting how all other pods will be scheduled going forward.
To see this in action, let’s imagine a situation where a cluster has two worker nodes, each with 2 cores of CPU.
A new pod gets created with a container that is requesting 1,500 millicores (1.5 cores) of CPU:
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: frontend
image: images.benchtest.dev/frontend:v1
resources:
requests:
cpu: "1500m"
The Kubernetes scheduler selects a node with enough capacity to fulfill the request and reserves that amount for the pod.
- Node 1: 1.5 / 2.0 Cores Reserved
- Node 2: 0.0 / 2.0 Cores Reserved
Now, let’s create a second pod requesting 1,000 millicores (1 core) of CPU:
kind: Pod
metadata:
name: backend
spec:
containers:
- name: backend
image: images.benchtest.dev/backend:v1
resources:
requests:
cpu: "1000m"
The scheduler sees that Node 1 only has 0.5 cores left (2.0 - 1.5 = 0.5), which isn't enough to satisfy the 1.0 core request. So, it must place the second pod on Node 2.
- Node 1: 1.5 / 2.0 Cores Reserved
- Node 2: 1.0 / 2.0 Cores Reserved
The scheduler has done its job correctly based on the requests. But what if the pods' actual usage is much lower than what they requested?
What if frontend only needs 250 millicores (0.25 cores) and backend only needs 500 millicores (0.5 cores)?
The problem becomes evident. The cluster state shows that 2.5 total cores are reserved, but only 0.75 cores are actually being used. Worse, Node 1 has 0.5 cores that are now "stranded", they are completely unused but cannot be scheduled by any pod requesting more than 0.5 cores.
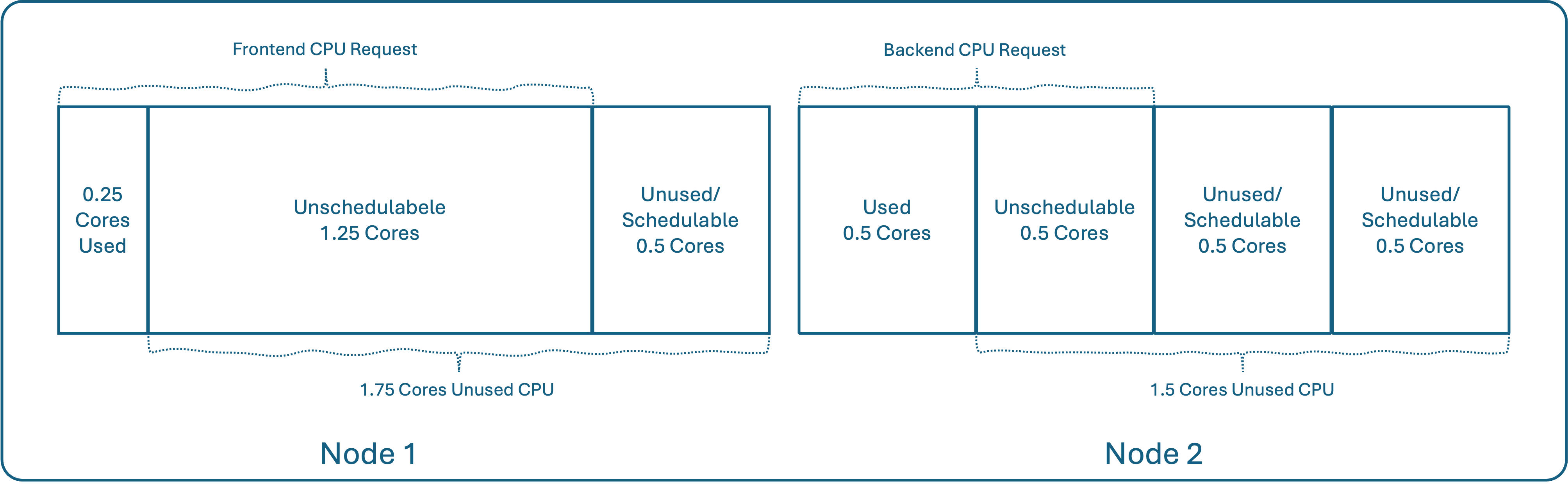
This wasted, unschedulable capacity ultimately increases the need for more (or bigger) nodes,and the costs associated with them. This is why it is so critical to size your pods correctly. [2]
How Kubernetes and Linux Handle Resource Management
To solve this, we need to understand the two layers of resource control. The core difference lies in their purpose:
- Kubernetes Resource Requests and Limits are configuration objects used by the Kubernetes control plane for scheduling and high-level policy.
- Linux Resource Controls (cgroups) are the low-level, kernel-based mechanisms that actually enforce those constraints on containers at runtime.
Kubernetes translates its requests and limits directly into Linux cgroup settings, but this translation isn't always intuitive.
A Deeper Dive into Kubernetes Resource Requests
As we saw, Resource Requests act as a scheduling guarantee. But how this guarantee is fulfilled at runtime differs significantly between CPU and memory.
How Memory Requests Work
When you set a memory request, you establish a guaranteed lower bound.
- Scheduling: The scheduler finds a node with enough unallocated memory to satisfy the request. If not, the pod remains
Pending. - Runtime Guarantee: Once scheduled, the container is guaranteed access to its requested amount of memory.
- The Risk of Bursting: A container can use more memory than requested if it's available. However, this "borrowed" memory can be reclaimed at any time if a new pod needs it, causing your pod to be terminated. This creates a painful trade-off between node density and application stability.
How CPU Requests Work
In contrast, CPU is a compressible resource. Instead of terminating a process, the system can throttle it.
- Scheduling: The scheduler finds a node with enough unallocated CPU capacity.
- Runtime Enforcement via CPU Shares: At runtime, a CPU request is translated into
cgroup CPU shares, which function as a relative weight. A container with1000mshares will get twice the CPU time as a container with500mshares, but only when the CPU is under contention. If the CPU is idle, a container can burst and use as much as it wants, leading to unpredictable performance across different nodes.
Resource Limits
Purpose: Hard Cap (Maximum) Defines the maximum amount of a resource the container is allowed to consume.
- CPU Limit: Exceeding the limit results in throttling, slowing down your application.
- Memory Limit: Exceeding the limit results in the container being terminated by the Out-Of-Memory (OOM) Killer.
In essence, Kubernetes provides the user-friendly interface and cluster-wide intelligence, while Linux provides the raw enforcement engine [3].
The Cost of Getting Resource Sizing Wrong
Rightsizing your workload directly impacts your cost, performance, and reliability. The consequences fall into two main categories:
1. Over-Provisioning: Unnecessary Costs
This is the exact problem we saw in our two-node cluster example. When you request more resources than your container uses, you pay for idle capacity.
- Increased Costs: You pay for resources that sit unused.
- Cluster Inefficiency: The scheduler reserves these resources, creating stranded capacity and making them unavailable for other workloads.
- Premature Scaling: Wasted resources prevent efficient pod placement, forcing unnecessary and costly node scale-up events.
2. Under-Provisioning: Performance Impact
When you request fewer resources than your container needs, you face severe performance and reliability issues.
- CPU Throttling: Containers are throttled, leading to high latency and application errors under load.
- OOMKilled Errors: Containers exceeding memory limits are abruptly killed, causing application crashes and service instability.
- Pod Eviction: Kubernetes may evict under-provisioned pods when nodes run low on memory.
Beyond Guesswork: A New Standard for Resource Management
Sizing container resources is a major challenge, stemming from a misunderstanding of resource requests and limits. When developers, who write the code, and operators, who manage it in production, aren't aligned, it creates a vicious cycle. Teams are left guessing, leading to either overprovisioning and wasted money or underprovisioning and critical performance incidents.
BenchTest closes this gap by making resource awareness an integral part of the development lifecycle. BenchTest empowers developers to answer a critical question before their code is ever deployed: "What resources does my application actually need to perform its job effectively?"
The ultimate result is a more efficient and reliable software ecosystem.
-
For Engineers: It means building applications that are not only correct but also well-behaved and cost-effective by design.
-
For Businesses: It means unlocking significant cloud cost savings, improving application stability, and increasing the velocity of development teams who can ship features with confidence.
By shifting resource optimization left, you're not just fine-tuning a configuration file; you're adopting a proactive standard of excellence for building and running cloud-native applications. The era of over-provisioning for safety or under-provisioning into failure is over. The future is building efficiently from the start.
Key Benefits of BenchTest:
- Early Detection: See container utilization metrics during development, not after a production deployment.
- Cost Optimization: Identify over-provisioned resources before they impact your cloud bill.
- Performance Assurance: Ensure your containers have adequate resources to handle production workloads.
- Reliability: Prevent OOM kills and performance degradation by setting appropriate limits.
- Data-Driven Decisions: Use performance test results to make informed resource allocation decisions.
How It Works:
- Run Performance Tests: Execute realistic load tests against your application.
- Monitor Resource Usage: BenchTest tracks CPU and memory consumption during tests.
- Analyze Results: Get detailed insights into actual resource needs vs. current allocations.
- Optimize Configuration: Adjust your Kubernetes resource requests and limits based on real data.
The Bottom Line
Resource sizing doesn't have to be guesswork. With BenchTest, you can:
- Eliminate waste by identifying over-provisioned containers.
- Prevent failures by ensuring adequate resource allocation.
- Reduce costs by optimizing resource utilization.
- Improve reliability by setting appropriate limits based on real usage patterns.
The relationship between Kubernetes scheduling and Linux cgroups is complex, but understanding it is crucial. BenchTest simplifies this process by providing the data you need to make informed decisions about resource allocation.
Start optimizing your container resources today!
References
[2] Practical tips for rightsizing your Kubernetes workloads
[3] Production Kubernetes: Building Successful Application Platforms
Ready to optimize your container performance?
Start profiling your containers with performance insights. No credit card required.